MacOS:使用Ollama在本地运行大型语言模型并连接至Zotero Translate等应用程序
MacOS:使用Ollama在本地运行大型语言模型,并连接到Zotero Translate等应用程序。MacOS的统一内存架构使得部署本地AI模型更加便捷轻松。

Ollama | What Ollama is?
Ollama 是一个开源项目,可以让我们在本地运行和管理大型语言模型(LLMs)。Ollama简化了在个人计算机上部署和使用开源大语言模型的流程。
Ollama is an open-source project that allows us to run and manage large language models locally (LLMs). Ollama simplifies the process of deploying and using open-source large language models on personal computers.
Ollama 主要特性 | Main Characters :
- 下载和管理模型: 可以使用 Ollama 下载各种预训练的 LLM 模型,例如 Llama 2 、Mistral 等。它会管理这些模型,包括存储、更新等。
- 本地运行模型: Ollama 允许在本地计算机上运行这些模型,这意味着数据不会离开个人设备,并且可以离线使用这些模型。
- 简单易用: Ollama 提供了简单的命令行界面,使得下载、运行和与模型交互变得非常容易。
- 跨平台支持: Ollama 支持 macOS 、Linux 和 Windows 系统。
- 可扩展性: Ollama 允许自定义模型和创建自己的模型。
- Download and manage models: You can use Ollama to download a variety of pre-trained LLM models, such as Llama 2, Mistral, and more. It manages these models, including storage, updates, and more.
- Run models locally: Ollama allows these models to be run on a local machine, which means that the data does not leave the personal device and the models can be used offline.
- Ease of use: Ollama provides a simple command-line interface that makes it very easy to download, run, and interact with models.
- Cross-platform support: Ollama supports macOS, Linux, and Windows.
Extensibility: Ollama allows you to customize models and create your own.
可以使用 Ollama 做什么?| Aim of download?
- 文本生成 Text Generation: 生成各种类型的文本,例如文章、诗歌、代码等。
- 问答 Q&A: 回答问题,提供信息。
- 文本摘要 summarizing: 总结长篇文章或文档。
- 代码生成 Coding: 生成代码片段或完整的程序。
- 创意写作 Writing: 进行创意写作,例如故事、剧本等。
- 本地 AI 开发 Local development: 为本地 AI 应用提供基础。
Ollama 的优点:
- 隐私 Pricacy: 数据保留在本地,无需担心数据泄露。
- 离线使用 Outline: 无需网络连接即可使用模型。
- 速度 High Speed: 本地运行通常比云端运行更快。
- 控制 In control: 可以完全控制模型和数据。
- 免费和开源 Free & Open-resouce: Ollama 是免费且开源的,任何人都可以使用和贡献。
总而言之,Ollama 是一个非常方便的工具,可以在本地轻松地使用大型语言模型,探索 AI 的强大功能,并保护个人数据隐私。
All in all, Ollama is a very handy tool to easily use large language models locally, explore the power of AI, and protect personal data privacy.
本篇博文主要基于MacOS系统进行演示,硬件基础为M4芯片的Mac Mini。得益于M芯片的统一内存架构,在Mac中部署LLM模型的便捷性进一步提高。
This blog post is mainly based on the MacOS system, and the hardware base is the Mac Mini with the M4 chip. Thanks to the M-chip's unified memory architecture, the ease of deployingLLM the model in the Mac has been further improved.
Ollama安装 | Installation
首先,我们访问Ollama官网进行下载即可:https://ollama.com/download ,下载MacOS版本后,将压缩包解压便直接得到了Ollama程序本体,双击便可以运行。
双击后,Ollama第一次启动会要求安装Ollama命令行工具,需要你输入一次Mac的系统密码,完成后关掉Ollama界面即可。此时,我们可以打开“终端”,使用ollama -v命令,即可查看当前安装的Ollama的版本。正常显示版本信息,就意味着安装成功。
First of all, we can visit the official website of Ollama to download: https://ollama.com/download, after downloading the MacOS version, decompress the compressed package and directly get the Ollama program body, and you can run it by double-clicking.
After double-clicking, the first launch of Ollama will ask you to install the Ollama command-line tool, which requires you to enter the system password of your Mac once, and then close the Ollama interface. At this point, we can open the "Terminal" and use the ollama -v command to see the version of Ollama that is currently installed. If the version information is displayed normally, it means that the installation is successful.

下载模型 | Download Models
我的Mac Mini M4位16G内存版本,因此运行的模型理论上在INT4量化下最大参数可以运行30B左右的模型。但是考虑到系统占用和M4的AI算力限制,这里我建议如果你使用的相同芯片和内存大小,最大选择15B左右的模型。
My Mac Mini M4-bit 16G memory version, so the model I run can theoretically run a model with a maximum parameter of about 30B under INT4 quantization. However, considering the system occupation and the AI computing power limitation of M4, here I suggest that if you use the same chip and memory size, choose a model of about 15B at most.
作为演示,我选择的是Qwen-2.5模型系列中1.5b的模型作为演示。我们打开Mac的“终端”,输入命令:
As a demonstration, I chose a model of 2.5b from the Qwen-1.5 model series as a demo. We open the "Terminal" of the Mac and enter the command:
ollama pull qwen2.5:1.5b该命令将下载qwen2.5:1.5b模型的模型文件,以进行后续的运行。更多模型,你可以访问ollama官网查看模型名称以及下载命令:https://ollama.com/search
This command will download the model file of the QWEN2.5:1.5b model for subsequent runs. For more models, you can visit the ollama official website to view the model name and download the command: https://ollama.com/search
如果你想直接在命令行开始运行模型,上述命令中的pull可以换为run,那么这样模型下载好以后,将会直接在命令行开始对话。不过本篇博文主要希望介绍如何将本地模型运行后,使用别的应用部署使用。因此这里使用pull下载后,我们进行下一步。
If you want to start running the model directly from the command line, you can replace the pull in the above command with run, so that after the model is downloaded, the conversation will start directly from the command line. However, the main purpose of this blog post is to introduce how to run the local model and deploy it with other applications. So here we use the pull after downloading and we move on to the next step.
通过API调用本地Ollama服务 | Start
刚才我们已经下载了qwen2.5:1.5b模型到本地,此时,通过ollama的本地端口已经可以对模型进行调用。这里首先以Zotero的翻译插件作为演示
Just now we have downloaded the QWEN2.5:1.5b model to the local computer, and at this time, the model can be called through the local port of ollama. Let's start with Zotero's translation plugin as a demonstration
Zotero PDF Translate插件接入本地AI模型 | Access in Zotero
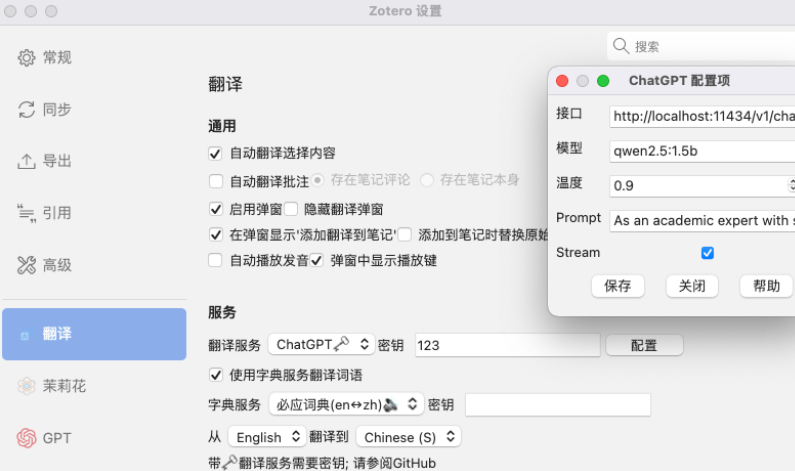
请确保你的Zotero已经提前安装了PDF Translate这个插件。我们打开Zotero设置,选择“翻译”,将翻译服务改为ChatGPT,然后密钥随便输入,因为Ollama本地API没有密钥。然后我们点击“配置”,在新弹出的窗口中,将接口更换为:https://localhost:11434/v1/chat/completions ,将模型更换为qwen2.5:1.5b,其他不用更改,点击保存后。
Make sure your Zotero has installed the PDF Translate plugin in advance. We open the Zotero settings, select "Translation", change the translation service to ChatGPT, and then enter the key casually, because the Ollama native API does not have a key. Then we click "Configure", in the new pop-up window, replace the interface to: https://localhost:11434/v1/chat/completions, replace the model with qwen2.5:1.5b, and do not need to change the rest, click Save.
此时,我们返回打开一篇英文文章,选中段落即可翻译。翻译过程中,你可以打开Mac的进程管理器,可以看到文字生成过程中,内存的占用会升高,这是正常现象,这也说明Ollama正在后台正常运行。
At this point, we go back to open an English article and select the paragraph to translate. During the translation process, you can open the Mac's process manager and you can see that the memory usage will increase during the text generation process, which is normal, which also means that Ollama is running normally in the background.

接入ChatGPT-Next-Web应用进行AI对话 | Access in NextChat
ChatGPT-Next-Web现在也叫NextChat,可以在Github下载其最新的应用版本。下载地址为:https://github.com/ChatGPTNextWeb/ChatGPT-Next-Web/releases
下载后,我们打开并在设置中,按下面的方式设置:
ChatGPT-Next-Web, also known as NextChat, is now available for download on Github for its latest version of the app. The download address is: https://github.com/ChatGPTNextWeb/ChatGPT-Next-Web/releases
Once downloaded, we open and in the settings, as follows:
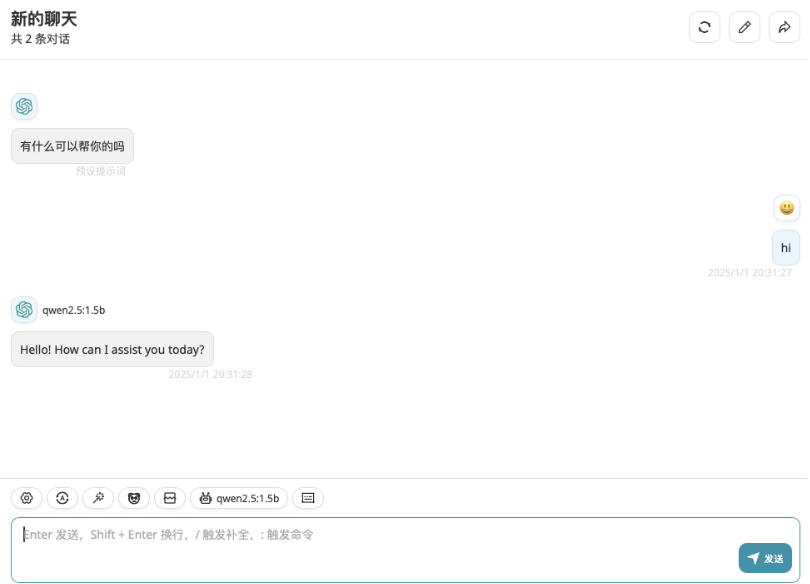
然后返回对话页面,新建一个对话,在模型选择中,选择qwen2.5:1.5b,即可使用本地部署的大语言模型开始对话。
Then return to the dialog page, create a new dialog, and select qwen2.5:1.5b in the model selection field to start a conversation using the large language model deployed locally.
总结 | summary
本地使用Ollama可以在对AI表现要求不高的翻译场景、简单标记工作中进行全时间段的使用,而且节约了服务商的API调用成本,同时处理重要数据时,还具有隐私保密作用。如果你有配置更高的GPU,可以尝试更大的模型。
后面将讲解一下如何使用CloudFlare Tunnel将Ollama服务进行内网穿透,提供公网可以访问的个人API调用服务。
The local use of Ollama can be used in translation scenarios and simple labeling work that do not require AI performance at all times, and it saves the cost of API calls for service providers, and at the same time, it also has a privacy and confidentiality effect when processing important data. If you have a GPU with a higher configuration, you can try a larger model.
Later, we will explain how to use CloudFlare Tunnel to penetrate the Ollama service over the intranet and provide a personal API call service that can be accessed over the public network.