

最近课程汇报,需要对选定的题目的研究进展和热点进行简单的展示。思索后认为如果能用词云展示最近新发的文章标题哪些词汇频率高会不会比较好。本来想用python生成词云,结果看到一个用R包制作词云的文章,非常不错。下面讲解一下具体流程。
演示环境:
R-4.2.1 Rstudio for Windows
具体步骤:
1.首先在Pubmed搜索自己想要查找的关键词,这里博主以自己专业相关的fish breeding(鱼类育种)作为搜索主题。
 2.这里我们点击save,保存所有结果到csv文档。
2.这里我们点击save,保存所有结果到csv文档。
 3,下载完成后我们用excel打开csv简单处理一下,只保留title一列,方便后面处理,这里我们把这个csv文件命名为fenci.csv
3,下载完成后我们用excel打开csv简单处理一下,只保留title一列,方便后面处理,这里我们把这个csv文件命名为fenci.csv
4.随后打开Rstudio,注意要先安装3个R包哦
Install.packages(c(‘jiebaRD’,’jiebaR’,’wordcloud2’))
5.现在我们可以先了解一下woker()的词汇分割功能。导入jiebaR后,调用函数如下
library(jiebaR)
sep<worker()
sep[file.choose()]
运行这几行代码后弹出来选择文件,选择我们刚才的fenci.csv,稍等两面在R的工作路径(不知道工作路径的运行getwd()查看,可以用setwd()修改)下就会多出来一个“fenci.segment+时间编号.csv”文件,里面就是已经分割好的内容。
 6.下面直接进行服务文件、分词、统计词频、排序,代码如下:
6.下面直接进行服务文件、分词、统计词频、排序,代码如下:
inp <- scan(file.choose(),sep="\n",what="",encoding="UTF-8")
time <- freq(seq[inp])
ordertime <- time[order(-time$freq),]
此时我们看一下ordertime的内容,已经是按顺序拍好的词频了
7.接着我们导出ordertime的内容到csv文本:
Write.table(ordertime,file=‘consequence.csv’,sep=’,’,row.names=FALSE,col.names= FALSE)
此时我们的R工作路径已经有了‘consequence.csv’文件,打开就是这样的
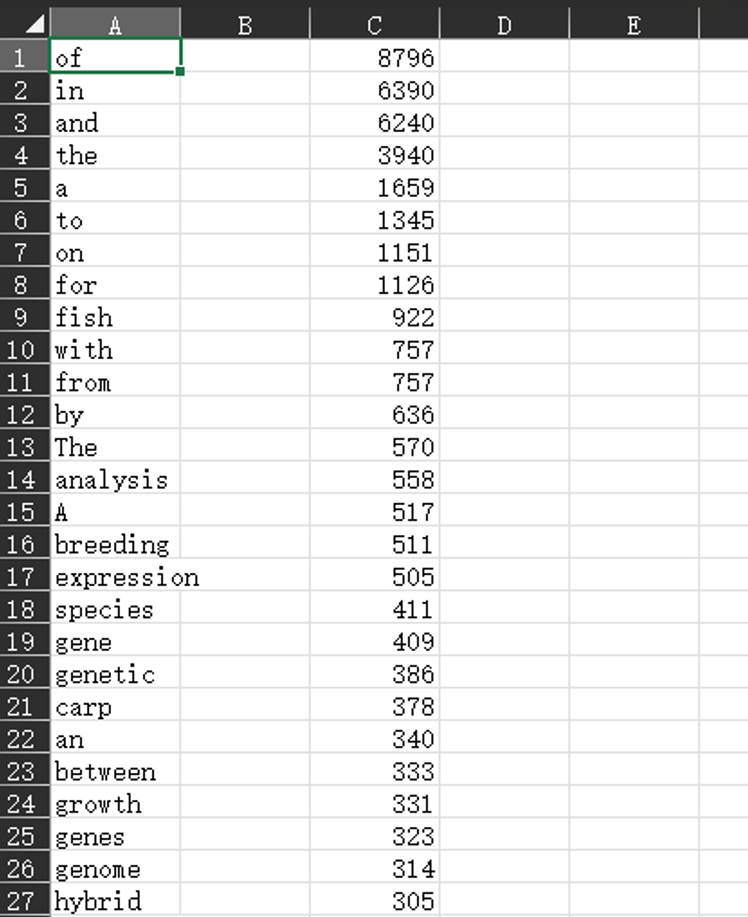 8.下一步筛选数据,因为我也还没找到太好用代码筛选的方法,所以我用的是手动过滤,就是对这两列数据开启筛选,分别对词汇和频率进行排序,基本上前面的都是不可用词汇。
然后我们按照频次降序排列,选取大概前200个词汇拿出来做一个筛选过滤,用于制作词云。过滤的规则可以根据你自己的需求来定。
这里选择200个词汇,是因为词云一次性放太多词不好看,可读性地,所以没必要把筛选后的上万个词都放上去。
8.下一步筛选数据,因为我也还没找到太好用代码筛选的方法,所以我用的是手动过滤,就是对这两列数据开启筛选,分别对词汇和频率进行排序,基本上前面的都是不可用词汇。
然后我们按照频次降序排列,选取大概前200个词汇拿出来做一个筛选过滤,用于制作词云。过滤的规则可以根据你自己的需求来定。
这里选择200个词汇,是因为词云一次性放太多词不好看,可读性地,所以没必要把筛选后的上万个词都放上去。
9.我这里就不筛选了,直接下一步,选择排名前100的词汇,其他的删掉,保存文件。做词云。
10.进入Rstudio,导入数据
 我们选择我们刚才处理过的consequence.csv
我们选择我们刚才处理过的consequence.csv
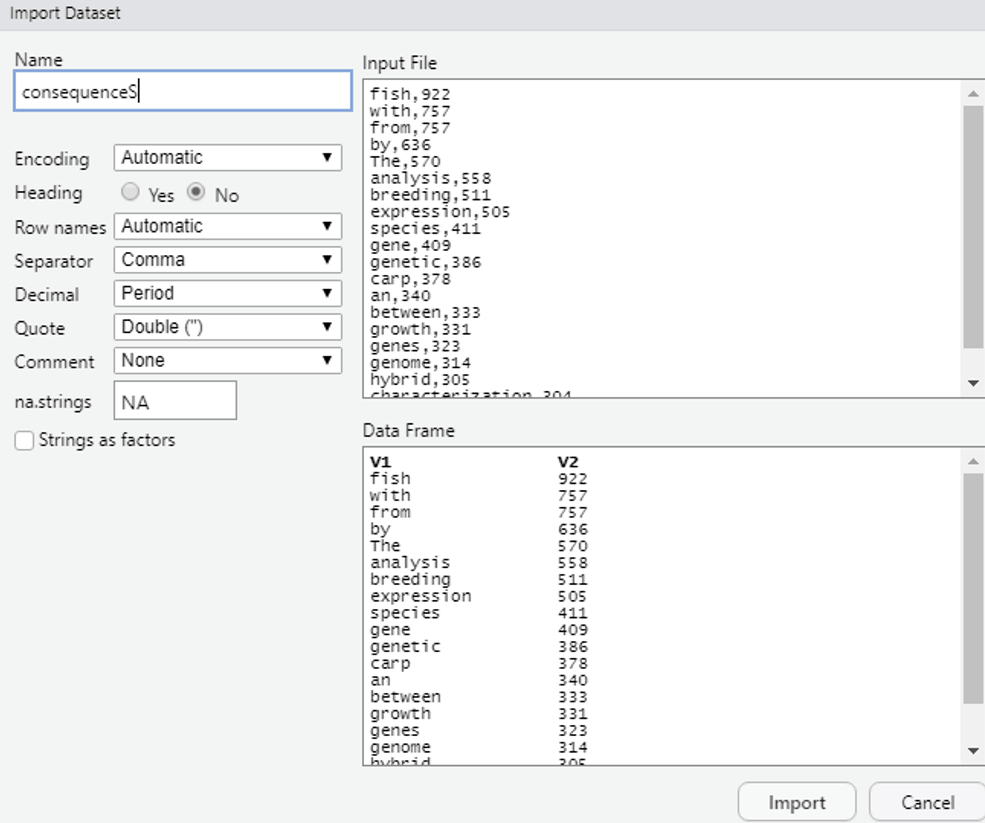 导入后输入下面的代码
导入后输入下面的代码
library(wordcloud2)
wordcloud2(consequence)
就可以看到viewer在生成词云啦(每次生成都不一样,可以根据需求自己设置参数)
